实验环境:
zookeeper-3.4.6 Spark:1.6.0 简单介绍: 本篇博客将从下面几点组织文章: 一:Spark 构建高可用HA架构 二:动手实战构建高可用HA 三:提交程序測试HA一:Spark 构建高可用HA架构
 Spark本身是Master和Slave,而这这里的 Master是指Spark资源调度和分配。
Spark本身是Master和Slave,而这这里的 Master是指Spark资源调度和分配。 负责整个集群的资源调度和分配。
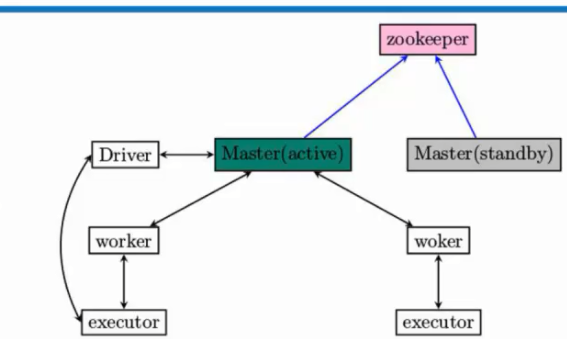
Worker是管理单个节点的资源。 这里面的资源主要指:内存和CPU。 1. Master-Slave模型非常easy出现单节点故障的问题。所以为了应用这个问题,解决的方法是通过Zookeeper来解决,在实际开发的时候一般都是三台,一个active,两个standby,当一个active挂掉后。Zookeeper会依据自己的选举机制,从standby的Master选举出来一个作为leader。
这个leader从standby模式变成active模式的话,做的最重要的事:是从Zookeeper中获取整个集群的状态信息,恢复整个集群的Worker,Driver,Application,这样才干接管整个集群的工作。而仅仅有它成功完毕之后,leader的Master才干够恢复成active的Master,才干够对外继续提供服务(作业的提交和资源的申请请求。
),当active的master挂掉以后,standby的master变成active的master之前我们是不能够向集群提交新的程序。可是在Zookeeper切换期间,在这个时间集群的执行时正常的,比如,一个程序依旧能够正常执行。
由于程序在执行之前已经向Master申请资源了,Driver与我们全部worker分配的executors进行通信。这个过程一般不须要master參与。除非executor有故障。Master是粗粒度分配。粗粒度的优点当Master出故障以后,能够让Worker和executor交互完毕计算。
2. Zookeper包括的内容有哪些:全部的Worker,Driver(代表了正在执行的程序)。Application(应用程序)二:动手实战构建高可用HA
3. 准备好Zookeeper安装包,下载zookeeper-3.4.6.tar.gz地址例如以下:http://apache.fayea.com/zookeeper/zookeeper-3.4.6/
- 将Zookeeper软件包移动到/usr/local/spark。
- 解压zookeeper.
[root@Master spark]# tar -zxvf zookeeper-3.4.6.tar.gz
- 在bashrc中加入zookeeper环境变量
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.6export PATH=/usr/local/eclipse/eclipse:/usr/local/idea/idea-IC-141.1532.4/bin:${ MAVEN_HOME}/bin:${ FLUME_HOME}/bin:${ SPARK_HOME}/bin:${ SPARK_HOME}/sbin/sbin::${ SCALA_HOME}/bin:${ JAVA_HOME}/bin:${ HADOOP_HOME}/bin:${ HADOOP_HOME}/sbin:${ HIVE_HOME}/bin:${ ZOOKEEPER_HOME}/bin:$PATH 7. 到zookeeper的conf文件夹下。将zoo_sample.cfg拷贝一份,由于在执行的时候zoo_sample.cfg会被删除。拷贝改名zoo.cfg,对zoo.cfg进行配置。
[root@Master conf]# cp zoo_sample.cfg zoo.cfg
8. 配置文件
[root@Master conf]# vim zoo.cfgdataDir=/tmp/zookeeperdataDir=/usr/local/spark/zookeeper-3.4.6/datadataLogDir=/usr/local/spark/zookeeper-3.4.6/logsserver.0=Master:2888:3888 server.1=Worker1:2888:3888server.2=Worker2:2888:3888
在/usr/local/spark/zookeeper-3.4.6/下创建data文件夹
[root@Master zookeeper-3.4.6]# mkdir data
10. 在/usr/local/spark/zookeeper-3.4.6/data 下创建标记每台机器的ID,最简单的方法:
[root@Master data]# echo 0>myid
11. 利用scp命令将在Master配置的zookeeper,复制到Worker1和Worker2节点上。12. 在spark-env.sh中配置Zookeeper信息,注意此时的Master_IP是master就不须要了。由于zookeeper中配置了.
-Dspark.deploy.recoveryMode: 表明整个集群的恢复和维护都是Zookeeper.-Dspark.deploy.zookeeper.url: 全部做HA机器。当中端口2181是默认端口。
-Dspark.deploy.zookeeper.dir: 指定Spark在Zookeeper注冊的信息
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60export SCALA_HOME=/usr/local/scala/scala-2.10.4export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.6.0/etc/hadoop//export SPARK_MASTER_IP=Master 这个IP就不须要了。export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,Worker1:2181,Worker2:2181 -Dspark.deploy.zookeeper.dir=/spark"export SPARK_WORKER_MEMORY=2gexport SPARK_EXECUTOR_MEMORY=2gexport SPARK_DRIVER_MEMORY=2Gexport SPARK_WORKER_CORES=2
13. 至此就全部安装完毕了,启动Master,Worker1和Worker2节点上的Zookeeper.
[root@Worker1 bin]# zkServer.sh startJMX enabled by defaultUsing config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfgStarting zookeeper ... STARTED[root@Worker2 bin]# zkServer.sh startJMX enabled by defaultUsing config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfgStarting zookeeper ... STARTED[root@Master bin]# zkServer.sh startJMX enabled by defaultUsing config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfgStarting zookeeper ... STARTED
14. jps查看进程,三台机器均启动成功。
[root@Master bin]# jps4005 Jps3685 SecondaryNameNode3978 QuorumPeerMain[root@Master bin]# jps4005 Jps3685 SecondaryNameNode3978 QuorumPeerMain[root@Worker2 Desktop]# jps3194 DataNode3453 QuorumPeerMain3503 Jps
15. 启动Spark集群。
[root@Master sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-Master.outWorker2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Worker2.outWorker1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Worker1.out
16. 可是此时Worker1和Worker2上的进程是Worker,而Master进程是master为什么?
由于在Spark集群配置中,slaves文件里我们此时指定了Worker节点。因此在启动的时候就会默认依据我们的配置启动Spark集群。
[root@Master sbin]# jps4067 Master3685 SecondaryNameNode3978 QuorumPeerMain4110 Jps[root@Master sbin]# ssh Worker1Last login: Sat May 7 17:29:50 2016 from master[root@Worker1 ~]# jps2881 Jps2484 DataNode2724 QuorumPeerMain2827 Worker[root@Worker1 ~]# exitlogoutConnection to Worker1 closed.[root@Master sbin]# ssh Worker2Last login: Sat May 7 17:24:00 2016 from worker1[root@Worker2 ~]# jps3569 Worker3194 DataNode3644 Jps3453 QuorumPeerMain
17. 到Worker1和Worker2上手动启动Master.
[root@Worker1 sbin]# ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-Worker1.out[root@Worker1 ~]# jps2484 DataNode2724 QuorumPeerMain2952 Master2827 Worker3052 Jps[root@Worker2 sbin]# ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-Worker2.out[root@Worker2 sbin]# jps3569 Worker3704 Master3194 DataNode3772 Jps3453 QuorumPeerMain
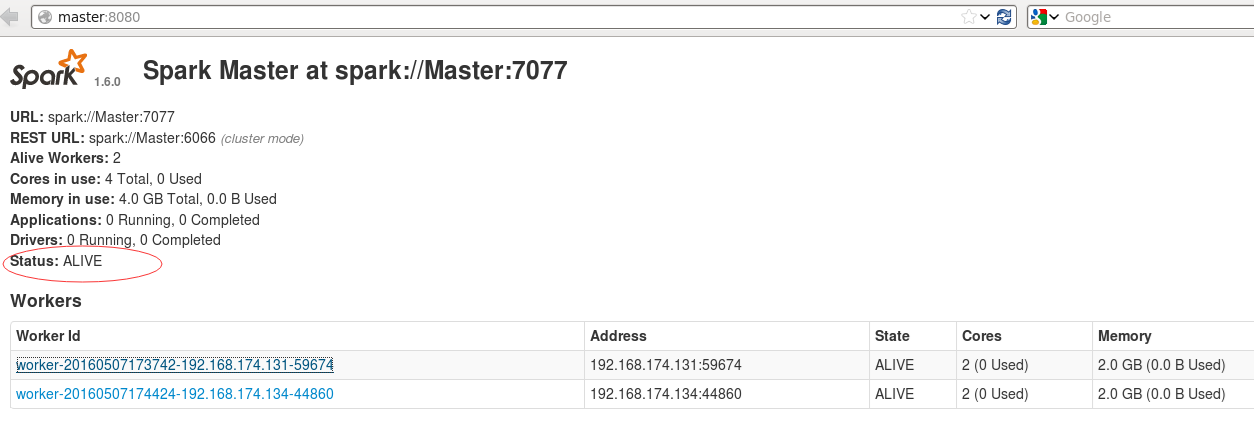
18. 通过web界面查看,Master是ALIVE.
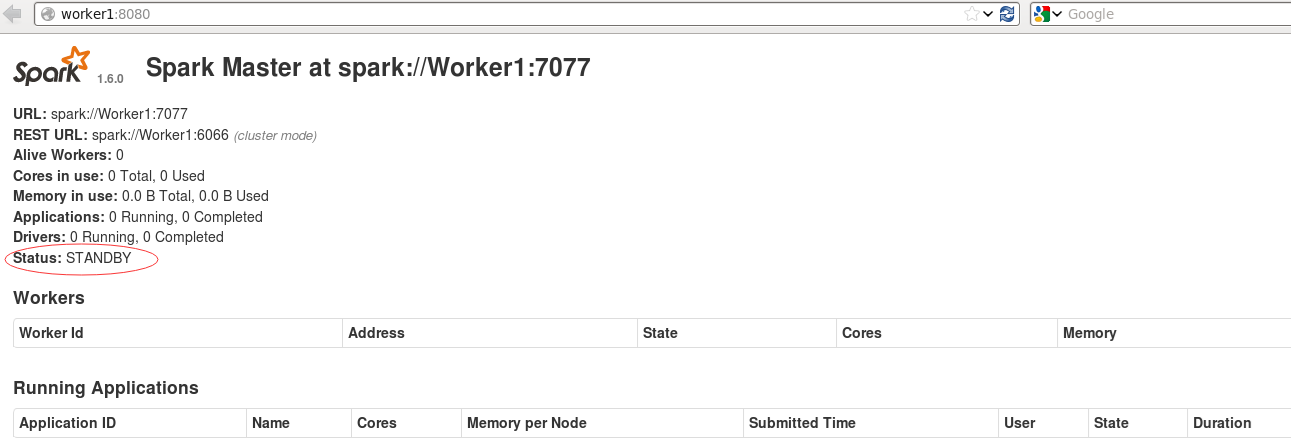
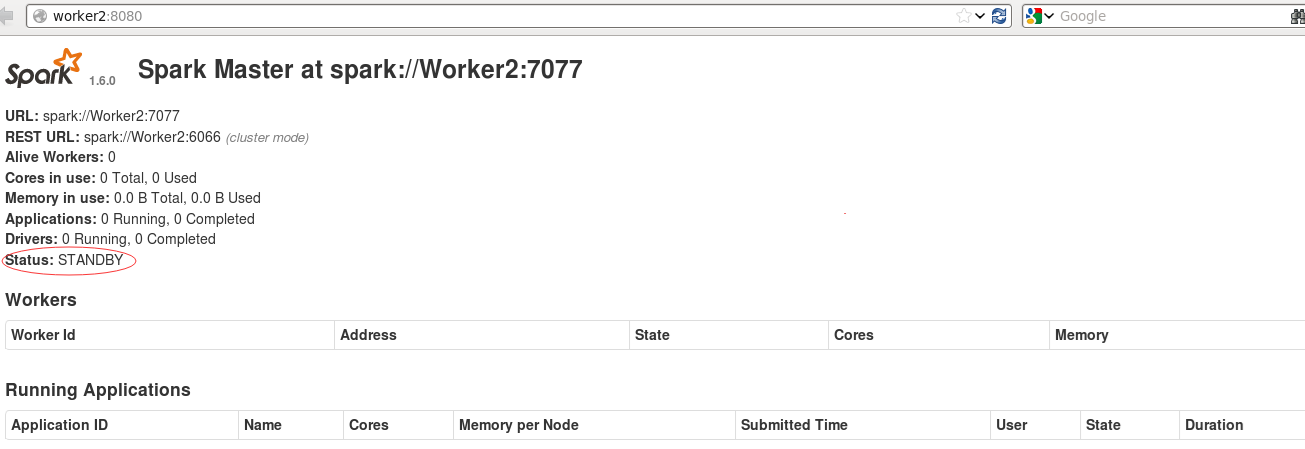
三:提交程序測试HA
1. 以集群的方式启动Spark-shell。由于此时受Zookeeper管理,因此在集群启动的时候,须要将三台HA中的Master都要写上。此时程序执行的时候肯定要向Zookeeper找active级别的Master。
[root@Master bin]# ./spark-shell --master spark://Master:7077,Worker1:7077,Worker2:7077
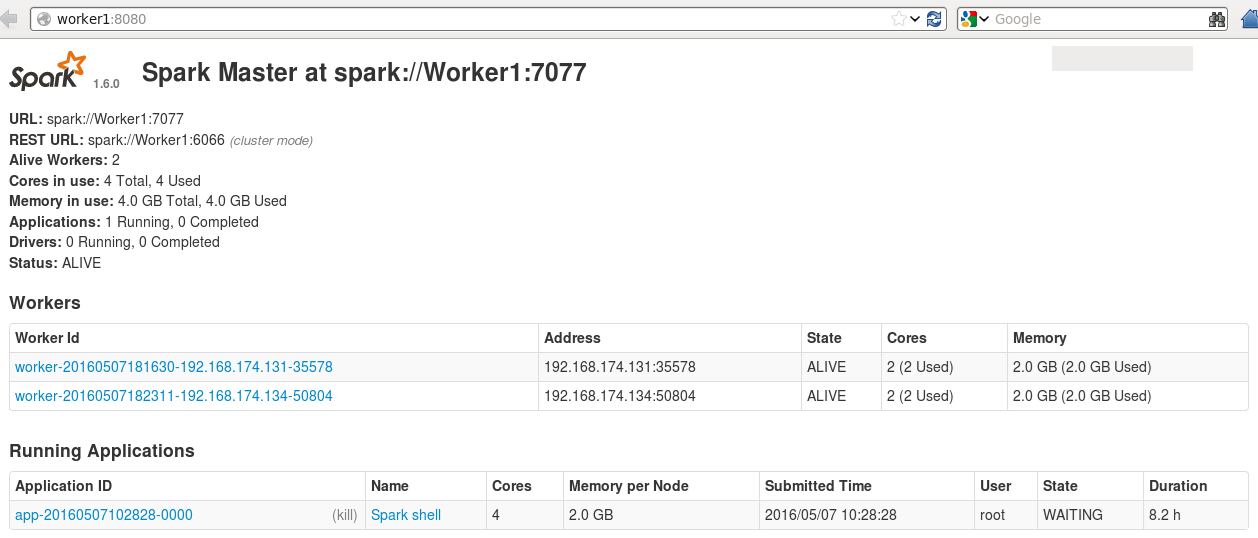
2. 启动spark-shell的时候通过日志能够看到,应用程序会连接三台Master.
16/05/07 10:28:20 INFO client.AppClient$ClientEndpoint: Connecting to master spark://Master:7077...16/05/07 10:28:20 INFO client.AppClient$ClientEndpoint: Connecting to master spark://Worker1:7077...16/05/07 10:28:20 INFO client.AppClient$ClientEndpoint: Connecting to master spark://Worker2:7077...
3. 关闭Master节点上的master进程。
[root@Master sbin]# ./stop-master.sh stopping org.apache.spark.deploy.master.Master
Zookeeper切换master,这个时候须要将Master上的master进行恢复给Worker1,因此须要延迟一段时间。
scala> 16/05/07 10:34:12 WARN client.AppClient$ClientEndpoint: Connection to Master:7077 failed; waiting for master to reconnect...16/05/07 10:34:12 WARN cluster.SparkDeploySchedulerBackend: Disconnected from Spark cluster! Waiting for reconnection...16/05/07 10:34:12 WARN client.AppClient$ClientEndpoint: Connection to Master:7077 failed; waiting for master to reconnect...16/05/07 10:35:05 INFO client.AppClient$ClientEndpoint: Master has changed, new master is at spark://Worker1:7077
4. 刷新web端,此时就无法链接上master进程。